Web Scraping là gì và nó hoạt động như thế nào trong Thế giới kỹ thuật số
Dữ liệu(Data) và thông tin là hai thuật ngữ thường được sử dụng thay thế cho nhau nhưng có một sự khác biệt đáng chú ý giữa chúng. Ví dụ, dữ liệu đề cập đến các bit thông tin, nhưng không phải bản thân thông tin. Mặt khác, Thông tin(Information) là một tập hợp dữ liệu được xử lý theo cách có ý nghĩa. Với lượng dữ liệu khổng lồ sẵn có trên internet, các phương pháp tiếp cận khác nhau như Web Scraping , Web Harvest(Web Harvesting) hoặc Web Data Extraction đang được sử dụng để tạo ra những hiểu biết sâu sắc có thể hành động và thay đổi trò chơi về việc sử dụng Internet . Nhưng chính xác thì chúng có nghĩa là gì trong thế giới trực tuyến. Hãy cùng xem!
Web Scraping hoạt động như thế nào
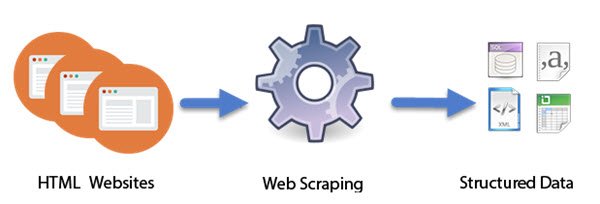
Các(Computer) chương trình máy tính được thiết kế dưới dạng các bot thông minh thực hiện công việc (Intelligent)Web Scraping . Không giống như quét màn hình, chỉ sao chép các pixel hiển thị trên màn hình, quét web trích xuất mã HTML bên dưới và cùng với nó, dữ liệu được lưu trữ trong cơ sở dữ liệu. Cách tiếp cận đã trở nên khá phổ biến. Trên thực tế, nó được coi là một trong những kỹ năng cần thiết để có được trong thế giới kỹ thuật số ngày nay. Nó có một số ứng dụng tuyệt vời trong việc biên dịch các tập dữ liệu lớn, nền tảng cho các kỹ thuật như-
- Phân tích dữ liệu lớn(Big Data Analytics)
- Học máy
- Trí tuệ nhân tạo(Artificial Intelligence)
Với sự mở rộng nhanh chóng của thông tin kỹ thuật số, việc truy cập Big Data thông qua phương pháp Web Scraping hoặc Web Data Extraction đã trở nên dễ dàng hơn nhiều. Phải nói rằng, Web Scraping có thể được sử dụng cho các doanh nghiệp kỹ thuật số dựa vào việc thu thập dữ liệu trong cả hai trường hợp Hợp pháp(Legitimate) hoặc bất hợp pháp. Cái trước bao gồm các Ví dụ về Scraping Web Lành(Benevolent Web Scraping Examples) tính trong khi cái sau có các ví dụ về Web Scraping độc hại(Malicious Web Scraping) .
Ví dụ về nạo web từ thiện
- Các bot của công cụ tìm kiếm(Search) đang thu thập thông tin một trang web, phân tích nội dung của nó để chỉ định thứ hạng dựa trên những phát hiện nhất định, như Google .
- Các trang web so sánh giá(Price) triển khai bot để tự động tìm nạp giá sản phẩm
- Các(Market) công ty nghiên cứu thị trường sử dụng máy cắt để trích xuất dữ liệu từ phương tiện truyền thông xã hội (ví dụ: để phân tích tình cảm, sở thích cá nhân, v.v.).
Ví dụ về Scraping trên web độc hại
Lừa đảo trên web(Web Scraping) cho các mục đích bất hợp pháp có thể gây ra tổn thất tài chính nghiêm trọng nếu dữ liệu bị trích xuất mà không có sự cho phép của chủ sở hữu trang web. Hai trường hợp sử dụng phổ biến nhất của Scraping web độc hại(Malicious Web Scraping) là cạo giá và đánh cắp nội dung.
- Đánh giá(Price Scraping) về giá - Các bot của Scraper kiểm tra cơ sở dữ liệu kinh doanh cạnh tranh để truy cập thông tin về giá, cắt giảm đối thủ và tăng doanh số bán hàng.(Scraper)
- Trộm cắp nội dung(Content Theft) - Hoạt động bất hợp pháp này bao gồm hành vi trộm cắp nội dung quy mô lớn từ một trang web mục tiêu. Các mục tiêu điển hình chủ yếu bao gồm danh mục sản phẩm trực tuyến và các trang web dựa trên nội dung kỹ thuật số để thúc đẩy hoạt động kinh doanh.
Hi vọng điêu nay co ich!

About the author
Tôi là kỹ sư phần mềm với hơn 10 năm kinh nghiệm thiết kế, xây dựng và bảo trì các ứng dụng dựa trên Windows. Tôi cũng là một chuyên gia thành thạo về xử lý văn bản, xử lý bảng tính và thuyết trình. Tôi có thể viết mô tả rõ ràng và ngắn gọn về mã, giải thích các khái niệm phức tạp cho các nhà phát triển mới làm quen và khắc phục sự cố nhanh chóng cho khách hàng.
Related posts
Không có Internet Connectivity, nhưng hiển thị như được kết nối với Web
Bitcoin, các Digital Currency là gì
Điều gì xảy ra với Online Accounts của bạn khi bạn chết: Digital Assets Management
Dark Web or Deep Web là gì? Làm thế nào để Access & Precautions
Lợi ích của việc tham gia Digital Detox và làm thế nào để đi về nó
Vô hiệu hóa Internet Explorer 11 dưới dạng standalone browser bằng Group Policy
Làm cách nào để sửa đổi hoặc thay đổi cài đặt WiFi Router của bạn?
Cách thiết lập Internet connection trên Windows 11/10
Cách tìm hiểu hoặc kiểm tra link or URL redirects ở đâu
Internet and Social Networking Sites addiction
Cách tiết kiệm pin khi duyệt web trong Internet Explorer
Cách sử dụng Shared Internet Connection tại nhà
Kiểm tra xem Internet Connection của bạn có khả năng phát trực tuyến nội dung 4k không
Các ứng dụng Edge and Store không kết nối với Internet - Error 80072EFD
Không thể kết nối với Internet? Try Complete Internet Repair Tool
Các cuộc tấn công bạo lực - Định nghĩa và Phòng ngừa
Internet không làm việc, kể một Update trên Windows 10
Di chuyển từ Internet Explorer sang Edge nhanh chóng sử dụng các công cụ này
Danh sách Best Free Internet Privacy Software & Products cho Windows 10
403 Forbidden Error and How để sửa nó là gì?